At AlliedModders we have somewhat of an inside term for especially difficult bugs: they are divine. Divine bugs usually have the following characteristics:
- They cannot be reproduced easily.
- They only occur on some installations or computers.
- They affect a large cross section of features.
- The solution ends up being extremely simple.
For example, the MOVAPS bug was internally referred to as a “divine bug.”
One of the most astonishing divine bugs we encountered was that SourceMod stopped working after a few days. Most people said “one to three days,” but no one ever said more than three days. The symptoms were that events and timers stopped firing, admin commands from client consoles all failed, and Timer Handles were leaking like crazy. SourceMod just came to a screeching halt.
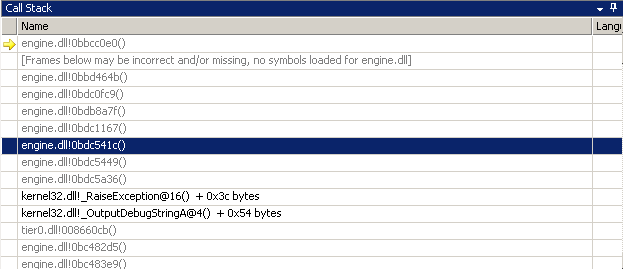
My first instinct was that the Handle system was failing. If SourceMod cannot allocate Handles, nothing works. WhiteWolf from IRC was kind enough to lend us GDB access to his server. I put breakpoints on the Handle System and waited for them to get hit. Three days passed, and his server stopped working. But the breakpoints were never hit!
If Handle allocations were succeeding, what was happening? I joined the server as an admin, and indeed I couldn’t use any commands. I put a breakpoint on the admin authentication callbacks. They never fired, which meant the admin’s steamid was never getting recognized. I put a breakpoint on the steamid checking function, and that breakpoint never got fired.
Now things were getting weird. The Steam ID checking function is called every second, so it meant something was wrong in the timer logic. I put a breakpoint on SourceMod’s global timer, which as we saw in previous articles, works like this:
float g_fTime = 0.0;
void OnFrame()
{
g_fTime += interval; //interval=0.015 on WhiteWolf's server, with 66 tickrate
}
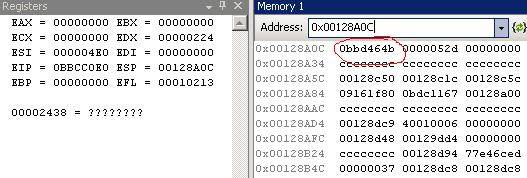
Imagine my surprise to find that g_fTime had stopped incrementing. To find out why I stepped through the function in assembly, and the crux of the matter became this instruction:
ADDSS xmm1, xmm0
The values of these registers were:
The time value was 262144, and the increment was 0.015. The instruction should have been adding these two values, and storing the result back in xmm1, but it wasn’t. It was doing nothing. Because of that, timed events were never firing, admins were not authenticating, and Timer Handles were piling up infinitely.
The next question was, how can ADDSS fail? Faluco and I first thought that some exception was being ignored, but after playing with the MXCSR register, that clearly was not the case. Amusingly, both faluco and cybermind came to the same conclusion independently: the problem was with the float type.
With single precision floats the value is composed as S*(2^E)*M, where 1 <= M <= 2. S is the sign value (1 or -1), E is the exponent value, and M is the mantissa value. In this case, S=1 and E=18 (262144 = 2^18). There are 23 bits to encode the mantissa fraction. What's the smallest fraction with 23 bits? That'd be about 1/(2^23), or 1.00000012. That means the smallest value after 262144 is 262144*1.00000012, or 262144.03.
After 262144 seconds, the precision of floats was less than the precision the server was ticking at, and ADDSS was rounding down, as 262144.015 could not be expressed. 262144 seconds is 72.8 hours, or three days. Finally, the bug could be solved. We simply changed the storage from single precision to double precision.
Was this a divine bug?
- It took three days to reproduce.
- It only happened on servers with a certain tickrate.
- It broke admin authentication and all timed functionality, and caused Handle table leakage.
- The fix was essentially changing one keyword.
The hardest bugs to find are often the simplest ones to fix. I wonder what the next divine bug will be.