This week a TF2 update started crashing SourceMod servers. It seemed to happen with random combinations of third party plugins, and would only happen after 20-30 seconds. Naturally, everyone pointed their fingers at us. After all, it only crashes when running SourceMod, right?
The call trace was incomprehensible:
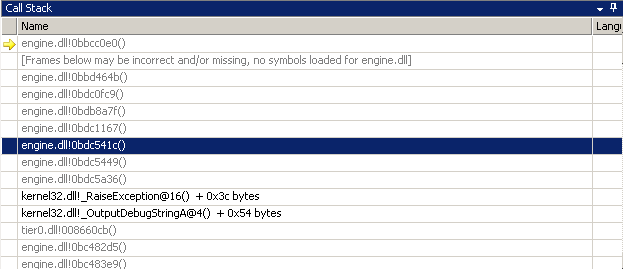
The first task was deducing the correct trace. I started off by inspecting the stack; that is, the memory at the ESP register:
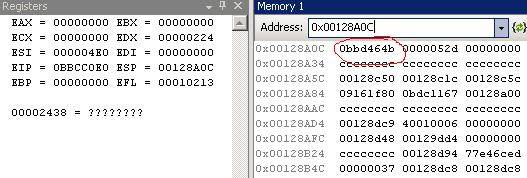
Where was 0x0BBD464B located? Looking at the modules list:

The address 0x0BBD464B was in the range of engine.dll. So I opened engine.dll in IDA, which said that the image base was 0x10000000:

Since in Visual Studio engine.dll was loaded at 0x0BB60000, I calculated 0x10000000 + (0x0BBD464B - 0x0BB60000), and got 0x1007464B. Jumping to this address in IDA:
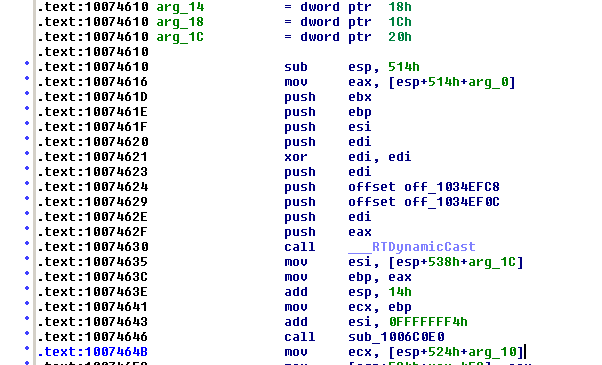
The address on the stack is the return address pushed from the call instruction on the second to last line. The goal was to find what preceded this function in the callstack, so I analyzed this function’s stack usage:
- 0x514 is subtracted from ESP.
- Four push instructions subtract 0x10 from ESP.
- Five push instructions subtract 0x14 from ESP.
- 0x14 is added to ESP.
Thus, we can say that 0x524 bytes are added to the stack in this function. So, next I inspected ESP+0x524, or 0x00128F30:
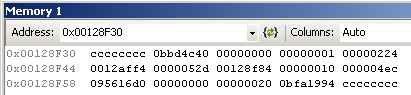
It looked like there was another engine function on the stack (0x0BBD4C40), but more interesting were its parameters. I inspected 0x0012AFF4 and got lucky:
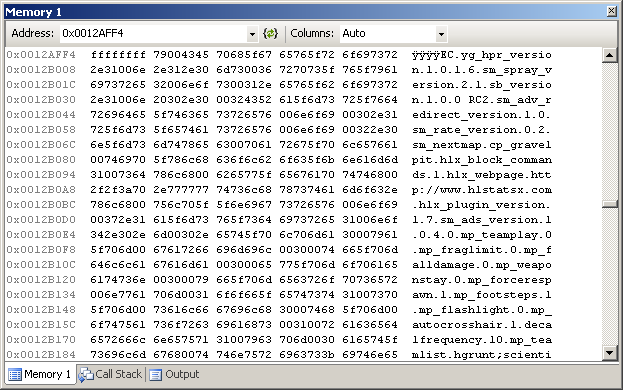
What’s this? It’s an A2S_RULES reply! Now I had enough data to make a guess: the server was crashing trying to reply to a rules query. I started a Team Fortress server on a weird port so that incoming queries would be blocked by my router. After about two minutes, there were no crashes. I started HLSW and queried my server. It crashed instantly.
Finally, the reason was confirmed. Third party plugins weren’t causing the crash. Third party plugins usually add public cvars, which get added to A2S_RULES replies. Valve had probably broken the mechanism which split up large query reply packets, and even a few extra public cvars were pushing it over the edge.
I sent a quick e-mail to Alfred Reynolds who confirmed the bug and said it would be fixed shortly. I’m glad the bug wasn’t on our side, but I wish Valve would release PDBs of their binaries.
(Note: I’ve posted this off-schedule so the next article will be on December 3rd. Enjoy your Thanksgiving!)
