AlliedModders recently passed its ten year anniversary. That’s literally crazy. At some point I’d like to do a longer post on its history and the people who made it happen – but today I wanted to talk about the evolution of our build process. It’s quite complicated for your average gritty open-source project – complicated enough that we wrote multiple custom build systems. Right now we’re pretty close to state-of-the-art: AMBuild 2 is a general-purpose, optimal-by-design DAG solver. But we started off in the dregs, and it took 10 years of iteration to get where we are now.
Without further ado…
The Beginning
The first project that would become part of AlliedModders was AMX Mod X. Felix Geyer (SniperBeamer) recruited me to the team, and I provided hosting. It was January of 2004, and there were two compilers you could use: GCC 2.95, and Visual Studio 6.0. The project had a single binary built from about 20 .cpp files.
On Linux it used a single Makefile. On Windows you had to run the Visual Studio IDE. For about six months our release process was entirely hand-driven. Even as we added more binary components, I’d build each one by hand, sort them into packages by hand, drop them into SourceForge FTP, then one by one add each package to a release.
As components became more complicated, I eventually got frustrated by Make’s lack of simple programmatic control. If you’re unfamiliar with GNU Make, it has something resembling the worst scripting language ever made. I couldn’t bring myself to touch it, and in August 2004 created two Perl scripts:
- Makefile.pl – A straight translation of the Makefile to Perl, but with more programmatic control over how and what gets built.
- package.pl (which I no longer have) – after building binaries by hand, this script would build packages and upload them to SourceForge.
Over the next year, AMX Mod X grew rapidly. The development team and community were very active, and the Half-Life 1 modding scene was at its peak. By July 2005, AMX Mod X had over 20 binary components and supported three platforms: Windows, Linux i386, and Linux AMD64. Releasing by hand took hours, and maintaining 20+ random copies of a Perl script was really difficult. Something had to change.
Fixed Pipeline Era
The first step was ditching Makefile.pl. I replaced it with a much cleaner Makefile. Most of the complexity was stripped away and reduced to a few variables and filters.
But I was still pretty new to software engineering, and made a major mistake – I didn’t separate the guts of the Makefile into something reusable. As a result the whole thing got copied and pasted to every component, and to components in other projects. To this day about 50 variations of that Makefile are scattered around, though it’s unclear whether anyone still uses them. Up until 2009 we were still syncing changes across them by hand.
The next step was automating all the component builds and packaging. AMX Mod X had weird packages. There was a “base” package, and then optional addon packages to supplement it. The steps for each package were similar, but they all built different sets of components. The result: I ended up writing something we affectionately called “the C# tool”: AMXXRelease. It had three pieces:
- A general pipeline for constructing an AMX Mod X package.
- An abstraction layer that decided whether to build via GNU Make or MSBuild.
- Classes for each package, usually just supplying filenames but sometimes adding custom steps to the pipeline.
The C# tool survived many years. Though it was a hard-coded tool written in a verbose, rigid framework, it got the job done. AMX Mod X continued to use it until 2014, when we finally ditched it as part of a transition to GitHub.
Interlude: SourceMod
In 2006, Borja Ferrer (faluco) and I secretly begun work on the next major AlliedModders project: SourceMod. SourceMod was a rewrite of AMX Mod X for the Half-Life 2 Source engine. By 2007 it was nearing ready to go public as beta, so I ported the C# tool. Everything was peachy. Until Half-Life Episode 1 came out.
At the time, it wasn’t conceivable to us that Valve would maintain multiple forks of the Source engine. Half-Life 1 was all we knew. Valve had never changed Half-Life 1 in a way that couldn’t be fudged with some detection and binary hacks. But Source was different – it was vast and complex compared to its predecessor. Valve began changing it frequently – first with Episode 1 – and then again with the Orange Box and Team Fortress. Now there were three versions of the Source engine, all totally binary incompatible. The same code didn’t even build across their SDKs, and linking was too complex for something like a “universal Source binary”.
Suddenly our Makefile and Visual Studio project files were getting ridiculously hairy. Not only did SourceMod have a dozen binary components, but it had to build each one multiple times with different parameters, across two different platforms. By mid-2009 we realized this was crazy and started looking at other options.
AMBuild 1: Alpha-Gen Building
I evaluated two build systems for SourceMod: CMake and SCons. CMake was a contender for “worst scripting language ever”. After a lot of futzing I concluded it was impossible to replicate SourceMod’s build, and even if I could, I didn’t want to see what it would look like. SCons came much closer, but it didn’t have enough flexibility. Source binaries required a precise linking order, and at the time SCons had too much automagic behavior in the way.
We needed something where we could template a single component and repeat its build over and over with small changes. We needed reasonably accurate minimal builds. We needed platform-independent build scripts, but also tight control over how the compiler was invoked. So in August 2009, I dove into Python and wrote our own general-purpose build tool, dubbed “AMBuild 1”.
I would describe AMBuild 1 as “rough”. It was definitely extremely flexible, but it was buggy and slow. Each unit of work was encapsulated as a “job”, but jobs did not form dependencies. It had some hardcoded, special logic for C++ to support minimal rebuilds, but since it was special logic, it broke a lot, and because it was recursive in nature (like Make), it was very slow. Since jobs didn’t form dependencies, they couldn’t be parallelized either. Everything ran sequentially. The API was also pretty grody. The root build file for SourceMod was somewhat of a nightmare.
But… it worked! Suddenly, supporting a new Source engine was just a matter of adding a new line in its central build file. It worked so well we began migrating all of our projects to AMBuild.
Over time, as always, things began to break down. By 2013 there were twenty versions of Source, and AMBuild 1 was nigh unusable. Minimal rebuilding was inaccurate; sometimes it rebuilt the entire project for no reason. Sometimes it produced a corrupt build. Builds were also EXTREMELY slow. A complete Windows build could took two hours, and multiple cores did nothing. There were so many headers in the Source SDK, and so many file scans for dependency checks, that merely computing the job set for an update could take 15 seconds.
AMBuild 2: Modern Era
Sometime in 2013 I found Tup and was immediately inspired. Tup “gets it”. Tup knows what’s going on. Tup knows what it is. Tup is what build systems should aspire to be. In short, it has two philosophies:
- Builds should be 100% accurate. Not 99% accurate, or 37% accurate, or “accurate if you clean or clobber”. They should be 100% accurate all the time.
- Builds should be fast, because waiting for builds is a waste of time.
The design of Tup is simple on the surface. Rather than recursively walking the dependency graph and comparing timestamps, it finds a root set of changed files, and then propagates a dirty bit throughout the graph. This new “partial graph” is what has to be built. In practice, this is much faster. In addition, Tup caches the graph in between builds, so if your build files change, it can compute which parts of the graph changed.
Well, that’s awesome. But… I didn’t want to take on Tup as a dependency for AlliedModders. I have a few reasons for this, and I’m still not sure whether they’re valid:
- Tup requires file system hooks (like FUSE) and I was worried about its portability.
- Tup is a C project, and not yet in Linux distros, so we’d have to tell our users to install or build it.
- AMBuild’s API, and of course Python, together make for a much better front-end than Lua.
- Tup didn’t seem to include external resources (for example, system headers/libraries or external SDKs) in its graph.
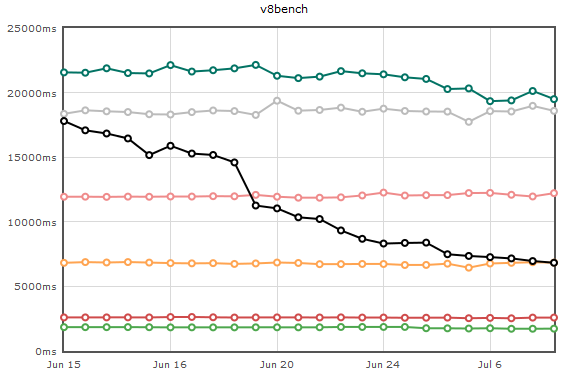
So I sat down and began rewriting AMBuild with Tup’s principles in mind. The result was AMBuild 2. With a real dependency graph in place, the core of the build algorithm became much simpler, and parellelizing tasks was easy. The API got a massive overhaul and cleanup. It took about two months to work all the kinks out, but in the end, my SourceMod builds took about a minute locally instead of 15. And with some smarter #include’ing, our automated builds went from 45 minutes to 2 minutes. The build scripts don’t look too bad, either.
What’s next?
AMBuild 2 isn’t perfect. Its biggest problems are scalability and internal complexity. I’m a huge fan of Python, and it’s nearly everywhere now. But it’s slow. Dog slow. AMBuild 2 would not scale to a codebase the size of Mozilla or Chromium. In addition, Python’s concurrency support is very bad, even taking into account the multiprocessing module. Most of AMBuild’s complexity is in its IPC implementation.
Early on in its development a common suggestion I got was to separate AMBuild into a front-end (the build API) and back-end (the build algorithm). I heard this theory float around for Mozilla’s build system too. CMake is structured this way. Separating the components out means they are replaceable: AMBuild 2’s frontend could generate Makefiles instead of an AMB2 DAG, or it could read Makefiles and parse them into a DAG.
I eventually concluded that didn’t make much sense. The goal of AMBuild 2 is not to provide a general backend or general frontend: it’s to produce correct builds as quickly as possible. In fact, it considers most other build systems to be broken and inferior. Taking an AMBuild project and generating Makefiles defeats its entire purpose.
However, there is something very useful that comes out of this separation, which is the ability to generate IDE project files for casual use or local development. Keeping this in mind, AMBuild 2 did separate its front-end from its back-end, but the API makes too many assumptions that don’t have clean mappings to IDE files. As we experiment with Visual Studio and XCode generators, we’ll probably have to iterate on the API.
Lastly, it’s worth nothing that part of what AMBuild solves is papering over an early design flaw in SourceMod: with proper abstractions, it wouldn’t need 20 different builds. In fact, over time we have moved a large amount of code into single-build components. Unfortunately, due to the complexity of what’s left and the Source SDK in general, it would be nearly impossible to completely eliminate the multiple-build steps.
Ok
There are very few projects I’m truly proud of, where I look back and have very few regrets. (One is IonMonkey, but that’s a story for another day.) AMBuild is one of them. It’s not particularly stellar or original, but we needed to solve a difficult problem, and it does the job very well. I wouldn’t be surprised if it takes another 10 years of iteration to make it perfect – but that seems to be how things work.











{kind=link}