A few days we released SourceMod 1.3 and suddenly got a few reports of crashing when clients disconnect. We couldn’t reproduce it, but a few users claimed they could. We had about ten minidumps to work with (they include a few KB of stack memory and that’s it).
All of the stack traces had a weird code address at the top and nothing else. Here’s two examples:
> 1673a14a() EAX = 0ED884B0 EBX = 00000000 ECX = 0EDAC948 EDX = 0EDA6A48 ESI = 0DFFA95E EDI = 100F0101 EIP = 1673A14A ESP = 0012DA09 EBP = 00000001 EFL = 00010282
> 0e531992() EAX = 0ED884B0 EBX = 00000000 ECX = 0EDAC948 EDX = 0EDA6A4 ESI = 0DFFA95E EDI = 100F0039 EIP = 0E531992 ESP = 0012DA09 EBP = 00000001 EFL = 00010282
These code addresses are weird because the debugger couldn’t map them to any loaded module. So they’re either dynamically generated/exploited, or garbage. What can we do with such little information? Surprisingly, a lot!
The first thing of interest was that ESP, the stack pointer, was not aligned correctly (it should be divisible by 4). This wasn’t the case in all minidumps, but it was a good hint, given that it was in the usual range for Windows main-thread stack addresses. The CPU was probably jumping to garbage memory, and decoded it to something that incremented ESP. So after stripping that extra theoretical increment off ESP, I could inspect its memory in Visual Studio:
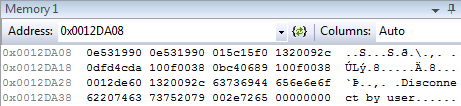
Whoa! A string on the stack suggests there was indeed something going on with client disconnects. Also, the value on the top of the stack – 0x0E531992 is very close to 0x0E531990. This was enough to form a wild guess: maybe the stack was misaligned, and the CPU picked the wrong return address to jump to. We can do better though.
The two most interesting binaries in the HL2 process are the engine and server. Let’s look at their address ranges in Visual Studio:
engine.dll 0BAF0000-0C10A000 server.dll 0DEB0000-0E3A4000
Two of the addresses close to the top of ESP fall into these ranges:
0x0012DA08 0e531990 0e531990 015c15f0 1320092c ..S...S.ð.\.,. .
0x0012DA18 0dfd4cda 100f0038 0bc40689 100f0038 ÚLý.8.....Ä.8...
0x0012DA28 0012de60 1320092c 63736944 656e6e6f `Þ..,. .Disconne
0x0012DA38 62207463 73752079 002e7265 00000000 ct by user......
Let’s take the outermost one first, since it may correspond to the stack frame that created that cool looking string. To go further, I like to use IDA – it’s a great disassembler and it has non-commercial and trial versions. With engine.dll loaded in IDA, all the addresses are wrong – luckily IDA can rebase the disassembly (Edit -> Segments -> Rebase Program):
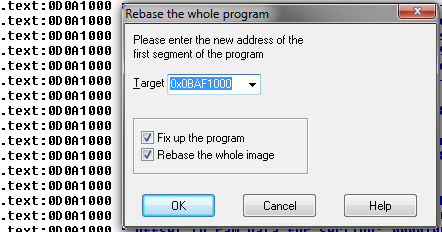
For some reason you have to add 0x1000 to get the right addresses – I don’t know why. Now I go to Jump -> Jump to Address, and type in 0bc40689, and find this:
.text:0BC40683 lea edx, [edi-4] .text:0BC40686 push edx .text:0BC40687 call eax .text:0BC40689 lea ecx, [esp+8]
Well, that’s kind of troublesome. IDA can’t tell where an indirect call will go. So I scroll around the function and look for hints, and get lucky. This is right above:
.text:0BC405F9 push 0 .text:0BC405FB push offset aPlayer_disconn ; "player_disconnect" .text:0BC40600 call edx .text:0BC40602 mov esi, eax
Again, this has something to do with player disconnects! Now I really want to know what function this is. Unfortunately Windows DLLS have symbols separated, but Linux binaries have them built-in. So I load the Linux version of the HL2 engine in IDA, and go to Jump -> Jump to Name, and type in aPlayer_disconn. By doing this I’m hoping the Linux binary has the same string, since IDA encodes string constants as unique names.
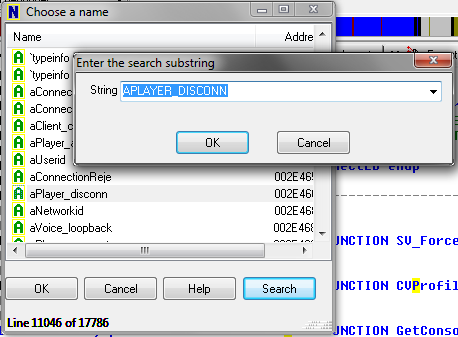
Here’s where IDA is extremely helpful – I click on aPlayer_disconn, and go to Jump -> Jump to cross reference:
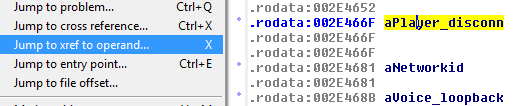
And now I get this:

So now our mystery call stack has CGameClient::Disconnect() in it. Progress! Now I want to know what that virtual call usually goes to. First I find the same call in the Linux binary. The Windows one had this:
.text:0BC4067D mov eax, [eax+0A8h] .text:0BC40683 lea edx, [edi-4] .text:0BC40686 push edx .text:0BC40687 call eax .text:0BC40689 lea ecx, [esp+8] .text:0BC4068D push ecx ; char .text:0BC4068E push offset aS_12 ; "%s" .text:0BC40693 push edi ; int .text:0BC40694 call sub_BBA2750
The Linux one is much harder to read because of GCC’s (asinine) PIC code, which IDA has trouble figuring out. But the basic pattern I’m trying to mentally match is:
- A virtual call that flows from a large virtual offset.
- The string “%s”.
- A non-virtual call.
In the Linux version, this looks really close:
.text:00102BE4 lea edi, (aS_3+2 - 343D64h)[ebx] .text:00102BEA mov edx, [eax] .text:00102BEC mov [esp+43Ch+var_438], ebp .text:00102BF0 mov [esp], eax .text:00102BF3 call dword ptr [edx+0ACh] .text:00102BF9 mov esi, [esp+43Ch+var_428] .text:00102BFD mov [esp+43Ch+var_438], edi .text:00102C01 mov [esp+43Ch+var_43C], ebp .text:00102C04 mov [esp+43Ch+var_434], esi .text:00102C08 call __ZN11CBaseClient10DisconnectEPKcz
Unfortunately IDA had trouble decoding the string reference – aS_3 points to “, %s” – but note it adds two bytes, making “%s”. Now I start a Linux server in GDB, and compute the address I want to break on. This is easy by taking the IDA difference and adding it to the function in the process:
(gdb) p _ZN11CGameClient10DisconnectEPKcz
$1 = {
(gdb) p/x 0x00102BF3 - 0x00102A70
$2 = 0x183
(gdb) p $1 + $2
$3 = (
(gdb) b *0xb75f4bf3
Breakpoint 2 at 0xb75f4bf3
Now I add and kick a bot (bold red text is my input):
(gdb) c
Continuing.
sv_cheats 1
bot
Cannot verify load for invalid steam ID [A:1:0:1]
kickid 2
Breakpoint 2, 0xb75f4bf3 in CGameClient::Disconnect ()
from /home/builds/common/srcds/orangebox/bin/engine_i486.so
(gdb)
Yay, it hit! Now I step into the assembly to see where this goes:
(gdb) display/i $pc
2: x/i $pc 0xb75f6bf3 <_ZN11CGameClient10DisconnectEPKcz+387>: call DWORD PTR [edx+0xac]
(gdb) si
0xb75edf00 in CGameServer::RemoveClientFromGame ()
from /home/builds/common/srcds/orangebox/bin/engine_i486.so
Now back in IDA, I go to Jump -> Jump to function and search for RemoveClientFromGame. Of interest in this function is the following code:
.text:000F9F6A mov ecx, ds:(serverGameEnts_ptr - 343D64h)[ebx] ... .text:000F9F81 call dword ptr [ecx+10h]
Since we have the symbol info, here I don’t have to do extensive guess work – this is almost definitely an IServerGameEnts pointer, a singleton interface the engine uses to feed information back to the actual game. Here it’s calling the offset for IServerGameEnts::FreeContainingEntity. Could this be the other address we saw on the stack, 0DFD4CDA? It seems likely, given that there is one pushed value in between, and the disassembly has one push as well. Let’s compare the target functions in source and binary. From loading server.dll in IDA:
.text:0DFD4CD0 mov eax,dword ptr [esp+4] .text:0DFD4CD4 push eax .text:0DFD4CD5 call sub_0DFFA920 .text:0DFD4CDA pop ecx .text:0DFD4CDB retn 4
The same function from hl2sdk/game/server/gameinterface.cpp:
void CServerGameEnts::FreeContainingEntity( edict_t *e ) { ::FreeContainingEntity(e); }
These seem really similar. So it seems like we might be crashing in ::FreeContainingEntity(), at a point where the stack depth is around 4 values. But looking at this function, it’s not really clear what could be happening:
void FreeContainingEntity( edict_t *ed ) { ... CBaseEntity *ent = GetContainingEntity( ed ); if ( ent ) { ed->SetEdict( NULL, false ); CBaseEntity::PhysicsRemoveTouchedList( ent ); CBaseEntity::PhysicsRemoveGroundList( ent ); UTIL_RemoveImmediate( ent ); } ... }
In HL2 parlance, UTIL_RemoveImmediate() means “immediately destroy and deallocate this entity”. The point at which the stack depth becomes 4 is around this call – but not exactly. At this point I gave up for the night and asked the user if he had any more information. But from this, I had the following guesses:
- Call stack that looked something like:
(?+0) server.dll!FreeContainingEntity() (?+1) server.dll!CServerGameEnts::FreeContainingEntity() (?+2) engine.dll!CGameServer::RemoveClientFromGame() (?+3) engine.dll!CGameClient::Disconnect()
- The CPU jumped to an invalid address somewhere.
- The invalid address may be from a return instruction and a misaligned stack.
Amazingly, he posted a working test case that involved adding and kicking a bot on a specific game. I tried this game, and managed to reproduce it! I narrowed the problem down to a minimal set of “extra junk running”, and from there SM developer Fyren noticed the problem pretty quickly.
SourceMod overwrites virtual table slots to “detour” function calls in between the engine and whatever game is running (in this case, Day of Defeat:Source). The slot number can differ between games, so it is specified in a configuration file. One of these configuration entries was missing, and SourceMod was accidentally overwriting the zeroth vtable entiry – the destructor! Now the sequence of events is clear:
- Engine tells the game that a client is disconnecting.
- Game destroys the client object.
- C++ calls the virtual destructor, but the vtable entry points to a SourceMod function.
- The Windows ABI uses a callee-pop convention on member functions. The virtual destructor should be popping no parameters, but the SourceMod function pops two, since the conventions don’t match.
- Once SourceMod’s replacement function returns, the CPU tries to load the return address, and gets garbage.
Phew.
Given that the patch that added this code baked for months, it’s amazing it slipped into a release. And for the record, it had two peer reviews. But there you have it. Sometimes it’s possible to draw blood from a minidump stone – but without a test case it’s unlikely we could have gotten this as quickly.



 , or
, or  possibilities. That means you can encode a pattern with just a 16-bit integer, and you can use that as an index into a 65,536-length array.
possibilities. That means you can encode a pattern with just a 16-bit integer, and you can use that as an index into a 65,536-length array.
 , where
, where  is the value of the pattern at that position. The denominator of the probability is the sum of those scores for the entire board. The numerator is the score of a specific location on the board.
is the value of the pattern at that position. The denominator of the probability is the sum of those scores for the entire board. The numerator is the score of a specific location on the board.
 . You don’t know the true value of
. You don’t know the true value of  ).
). slot machines, each expressed as a random variable
slot machines, each expressed as a random variable  . Once again, you don’t know the true value of any
. Once again, you don’t know the true value of any  . How can you choose the right slot machine such that you minimize your losses? That is, you want to minimize the loss you incur from not always playing the most optimal machine.
. How can you choose the right slot machine such that you minimize your losses? That is, you want to minimize the loss you incur from not always playing the most optimal machine. . You can then use this information to play on the observed best machine, but that might not end up being the most optimal strategy. You really need to balance exploration (discovering
. You can then use this information to play on the observed best machine, but that might not end up being the most optimal strategy. You really need to balance exploration (discovering }{child.visits}}")
{kind=link}
{kind=link}