Last week I gave an introduction to Computer Go, and left off mentioning that the current hot topic is Monte-Carlo methods. These methods use repeated random gameplay to sample a position’s value.
How do programs use random gameplay to reach a good conclusion? While you can sample specific positions, you only have finite time. How do you balance simulating one interesting position over another?
A few years ago a breakthrough algorithm was published, called UCT (Upper Confidence Bounds applied to Trees). The algorithm attempts to minimize the amount of sampling needed to converge to an acceptable solution. It does this by treating each step in the game as a multi-armed bandit problem.
Bandit Problem
A bandit is a slot machine. Say you have a slot machine with some probability of giving you a reward. Let’s treat this reward as a random variable  . You don’t know the true value of , but by playing the slot machine repeatedly, you can observe an empirical reward, which is just an average (
. You don’t know the true value of , but by playing the slot machine repeatedly, you can observe an empirical reward, which is just an average ( ).
).
Now consider having  slot machines, each expressed as a random variable
slot machines, each expressed as a random variable  . Once again, you don’t know the true value of any
. Once again, you don’t know the true value of any  . How can you choose the right slot machine such that you minimize your losses? That is, you want to minimize the loss you incur from not always playing the most optimal machine.
. How can you choose the right slot machine such that you minimize your losses? That is, you want to minimize the loss you incur from not always playing the most optimal machine.
Well, if you knew the true values of each machine, you could just play on the one with the greatest reward! Unfortunately you don’t know the true values, so instead you conduct trials on each machine, giving you averages  . You can then use this information to play on the observed best machine, but that might not end up being the most optimal strategy. You really need to balance exploration (discovering ) with exploitation (taking advantage of the best ).
. You can then use this information to play on the observed best machine, but that might not end up being the most optimal strategy. You really need to balance exploration (discovering ) with exploitation (taking advantage of the best ).
A paper on this problem published an algorithm called UCB1, or Upper Confidence Bounds, which attempts to minimize regret in such multi-armed bandit problems. It computes an upper confidence index for each machine, and the optimal strategy is to pick the machine with the highest such index. For more information, see the paper.
UCT
Levente Kocsis and Csaba Szepesvarí’s breakthrough idea was to treat the “exploration versus exploitation” dilemma as a multi-armed bandit problem. In this case, “exploration” is experimenting with different game positions, and “exploitation” is performing Monte-Carlo simulations on a given position to approximate its . UCT forms a game tree of these positions. Each node in the UCT tree stores and a “visit” counter. The confidence index for each node is computed as:
}{child.visits}}")
Each run of the algorithm traverses down the tree until it finds a suitable node on which to run a Monte-Carlo simulation. Once a node has received enough simulations, it becomes “mature,” and UCT will start exploring deeper through that position. Once enough overall simulations have been performed, any number of methods can be used to pick the best action from the top of the UCT tree.
How this all worked confused me greatly at first, so I made what is hopefully an easy flow-chart diagram. In my implementations, UCT starts with an empty tree (save for the initial moves the player can make).
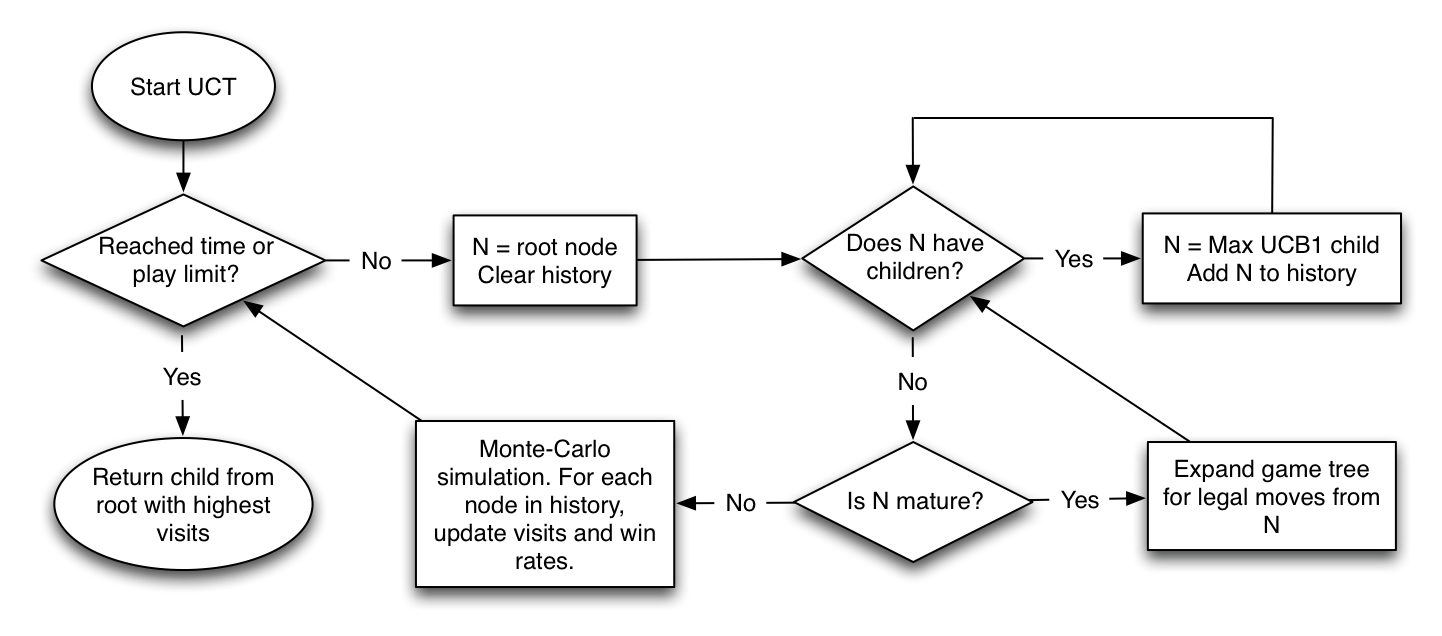
UCT converges to an acceptable solution very quickly, can be easily modified to run in parallel, and can be easily interrupted. It has seen massive success; all competitive Go programs now use it in some form.
Levente’s paper: click here
Next week: Monte-Carlo simulations and my project.
We find that our clients have different sized enterprises at different stagesof development. Some are new and emerging, while others are well established. Some have large budgets, while others operate with more of a ‘shoe-string’ approach. Whatever your needs are, our professional web designers and developers are available and ready to help you.
Hm. Your latex installation seems to be broken? :/
Thanks, fixed!
I don’t think it works exactly as you written.
But it is nice to read anyway ;)
Today i spent 300 bucks for platinium roulette system ,
i hope that i will earn my first $$ online
play piano by ear
I’m really loving the theme/design of your site. Do you ever run into any internet browser compatibility problems? A handful of my blog audience have complained about my site not working correctly in Explorer but looks great in Chrome. Do you have any tips to help fix this issue?
Heya I am a newbie to your website. I found this page and it is really informative. I wish to give something back.
Resulta maravilloso todo lo dicho aquí. Las reflexiones y los contenidos me han sugerido muchas cosas, así que seguiré investigando.
Heya I am a newbie to your website. I found this page and it is really useful. I wish to give something back.
Great post here!
fantastic points altogether, you simply gained a emblem new reader.
What may you suggest in regards to your publish that you simply made some days ago?
Any positive?