While working on a project, I was wondering how to most efficiently implement string internalization. String “interning” is when two strings that compare true always have the same reference. This is quite nice as you can test if two strings are equal by just comparing their pointers.
It seems everyone uses hash tables for this, and indeed when I asked someone with more VM experience, he suggested using hash tables as well. I was still curious though, especially since SourceMod has a fancy-pants compressed “double-array” trie implementation. We knew that insertion time was poor, but I secretly hoped that this cost would be amortized over the much faster retrieval case.
I took a dump of ~5MB of plugin text from the forums and extracted all syntactically valid identifier tokens (including ones found in comments and strings). In total I had 553,640 strings, of which 19,852 were unique. This seems pretty reasonable as people tend to use similar names for identifiers. I set up four benchmarks:
- std::map<std::string, int> — Typical STL container (red-black tree I think)
- SourceMod::KTrie<int> — SourceMod’s Trie container
- SourceHook::THash<const char*, int> – SourceHook’s “TinyHash,” chained hash table
- SourceHook::THash<std::string, int> – Same, with more allocation involved
As a note, “TinyHash” is one of the first ADTs I tried to write, and it shows. Its stock find() function iterates over the whole table, instead of computing a hash, which is really slow. I filed a bug on this and hacked up my local copy to benchmark.
Each test gets run twice. The first “batch” run goes over all identifiers and inserts them if they are not already in the container. The second “retrieval” run does the same thing, except now there will be no string insertions since the table is populated.
Here’s the results, in milliseconds. I used the Intel C++ Compiler, version 10, on my Macbook Pro (2.4GHz Core 2 Duo, 4GB RAM).
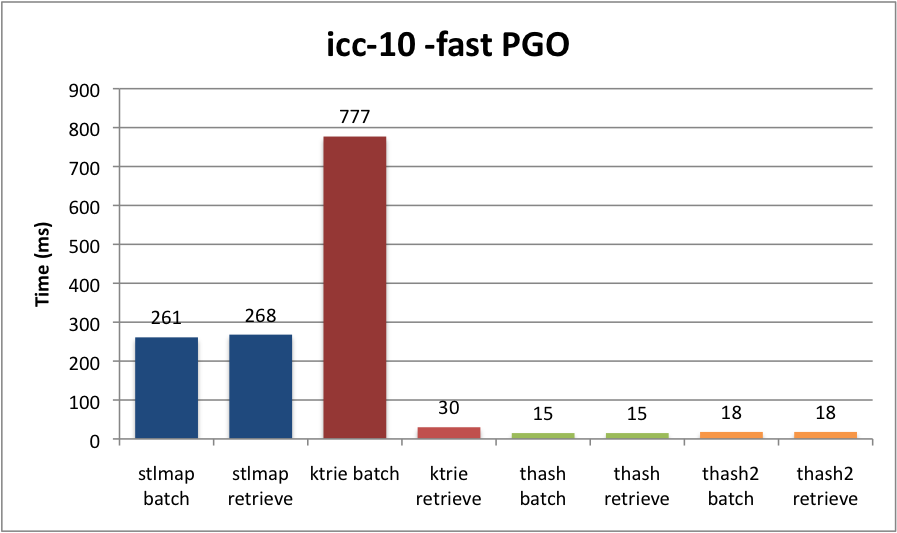
Whoa! Everyone was right. Well, I knew that insertion on our Trie was pants, but I was surprised to see that the cost was in no way amortized. In fact, it wasn’t even faster on retrieval! Why? I don’t know (yet), but if I had a guess, it’s because our Trie has to peek at memory a lot. David Gregg explained to me that the advantage of tries is sorting. He also theorized it might be faster on long strings, which is in line with my original benchmarks ages ago, where I used very long randomized strings. (Tries are also good for compression.)
Well, I has sad. Looks like we’ll be ditching KTrie for a chained hash table. At least for string interning. Someone is welcome to request a hash table ADT for SourceMod scripting as well.
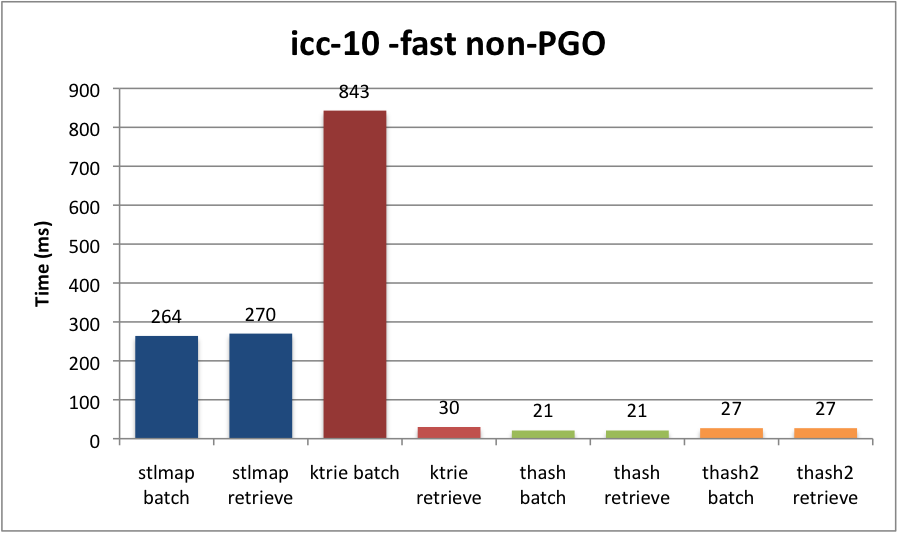
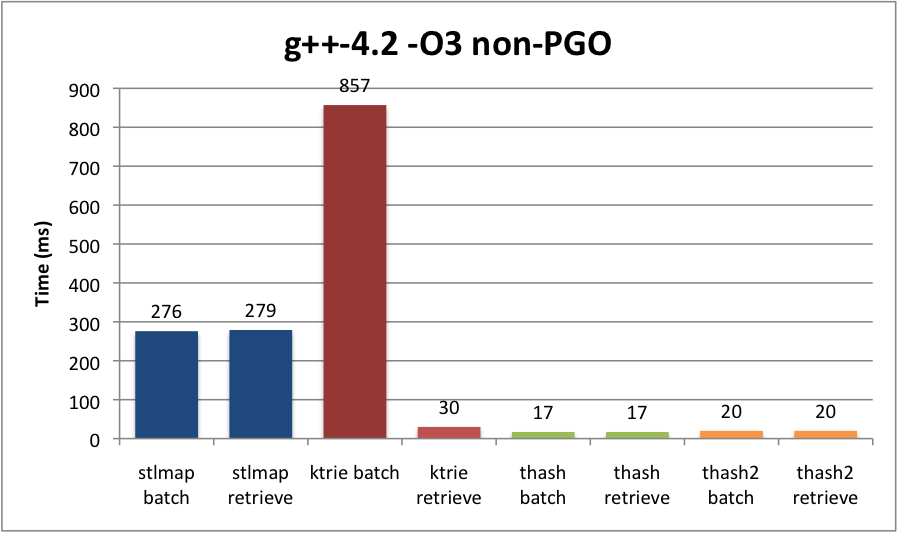
I also benchmarked non-PGO ICC and non-PGO g++-4.2 if you would like to see other compilers.
{kind=link}
{kind=link}
Note 1: Go article returns next week.
Note 2: Firefox 3.5 comes out tomorrow (June 30th!)
Explain to me how this trie works that insertion is so much slower than lookup..
Our implementation was based on “Double Array Tries.” Memory is a large vector of nodes. Each node has a “base” and “parent” pointers to other nodes. “Base” gives you a node N such that N plus a character will get you to the next piece of a string. “Parent” lets you tell whether N+c is a valid transition, or a collision. In this manner you can get a pretty compact representation that doesn’t need linked lists.
If you have a string “XYZ”, you arrive at the node for that key by computing something like
memory[memory[memory[‘X’].base + ‘Y’].base + ‘Z’]
So that’s probably what leads to cache misses.
Insertion is slow because collisions are really awful. If a transition collides, you have to break out all transitions coming from the parent node and move them somewhere else. This requires going over the entire vector and finding a suitable mapping, and if there is none, growing the vector.
The paper proposed a way to ameliorate this but there’s no helping that insertion is fundamentally slow. Of course there are other trie storage mechanisms. I don’t know much about them, though surely linked-list ones will not have collision insertion problems.
Reference:
* An Efficient Implementation of Trie Structures, by
* Jun-ichi Aoe and Katsushi Maromoto, and Takashi Sato
* from Software – Practice and Experience, Vol. 22(9), 695-721 (September 1992)
Might be worth benchmarking with std::unordered_map to see how that compares to the hash table.
I am definitely happy to locate this site. I wanted to say thanks for your time for this awesome post. I definitely enjoyed reading it and I have you bookmarked to check out new articles you create.
It’s hard to locate knowledgeable individuals on this, but you sound like you know what you’re talking about! Thanks
I am often blogging and I really respect your content.
An interesting dialogue is worth a comment. I think that you should write extra on this topic, it may not be a taboo subject however generally individuals are not brave enough to talk on such things. Thanks!
There may be noticeably a bundle to know about this. I assume you made sure nice factors in features also.
Good post. I be taught something more difficult on completely different blogs everyday. It would always be stimulating to read content from other writers and follow slightly something from their store. I’d choose to make use of some with the content on my blog whether you don’t mind. Natually I’ll provide you with a hyperlink on your web blog. Thanks for sharing.
http://www.monogrambusinesscards.net/shopping_cart/product_id/b5bd66d4bae3aa6a31c0f931b38999ec.html There is no reality except the one contained within us. That is why so many people live such an unreal life. They take the images outside them for reality and never allow the world within to assert itself.
Technical http://www.bridalshowerthemes.info/2015/01/05/black_and_white_stripes_gold_glitter_bridal_shower_invitation/ skill is mastery of complexity, while creativity is mastery of simplicity.
The FCC limits broadband innovation?! Are they really calling net neutrality a limitation http://www.peacockbridalshowerinvitations.com/catalogue/161259362138553519/peacock_bridal_shower_invitation/ to innovation? Fuck these The obviously have no clue what they are talking about
You can definitely see your enthusiasm within the work you write.
The world hopes for even more passionate writers like you who are
not afraid to say how they believe. Always follow your heart.